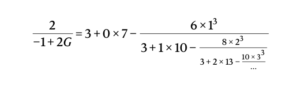If \(\alpha\) is an algebraic number, the normlized trace of \(\alpha\) is defined to be
\( \displaystyle{T(\alpha):=\frac{\mathrm{Tr}(\alpha)}{[\mathbf{Q}(\alpha):\mathbf{Q}].}}\)
If \(\alpha\) is an algebraic integer that is totally positive, then the normalized trace is at least one. This follows from the AM-GM inequality, since the normalized trace is at least the \(n\)th root of the norm, and the norm of a non-zero integer is at least one. But it turns out that one can do better, as long as one excludes the special case \(\alpha = 1\). One reason you might suspect this to be true is as follows. The AM-GM inequality is strict only when all the terms are equal. Hence the normalized trace will be close to one only when many of the conjugates of \(\alpha\) are themselves close together. But the conjugates of algebraic integers have a tendency to repel one another since the product of their differences (the discriminant is also a non-zero integer.) In an Annals paper from 1945, Siegel (bulding on a previous inequality of Schur) proved the following:
Theorem [Siegel] There are only finitely many algebraic integers with \(T(\alpha) < \lambda\) for \(\lambda = 1.7336105 \ldots\)
Siegel was also able to find that the only such integers with noramlized trace at most \(3/2\) are \(1\) and \((3 \pm \sqrt{5})/2 = \phi^{\pm 2}\) for the golden ratio \(\phi\) (We will also prove this below). On the other hand (generalizing these examples), one has
\(\displaystyle{T(\left((\zeta_p + \zeta^{-1}_p)^2\right) = 2 \left(1 – \frac{1}{p-1} \right),}\)
and hence the optimal value of \(\lambda\) is at most \(2\). Sometime later, Smyth had a very nice idea to extend the result of Siegel. (An early paper with these ideas can be found here.) Consider a collection of polynomials \(P_i(x)\) with integral coefficients, and suppose that
\(Q(x) = -\lambda + x \ – \sum a_i \log |P_i(x)| \ge 0\)
for all real positive \(x\) where \(Q(x)\) is well-defined, and where the coefficients \(a_i\) are also real and non-negative. Now take the sum of \(Q(x)\) as \(x\) ranges over all conjugates of \(\alpha\). The key point is that the sum of \(\log |P_i(\sigma \alpha)|\) is log of the absolute value of the norm of \(P_i(\alpha)\). Assuming that \(\alpha\) is not a root of this polynomial, it follows that the norm is at least one, and so the log of the norm is non-negative, and so the contribution to the sum (since \(-a_i\) is negative) is zero or negative. On the other hand, after we divide by the degree, the sum of \(\lambda\) is just \(\lambda\) and the sum of \(\sigma \alpha\) is the normalized trace. Hence one deduces that \(T(\alpha) \ge \lambda\) unless \(\alpha\) is actually a root of the polynomial \(P_i(x)\). So the strategy is to first find a bunch of polynomials with small normalized traces, and then to see if one can construct for a constant \(\lambda\) as close to \(2\) as possible some function \(Q(x)\) which is always positive.
One can make this very explicit. Suppose that
\(\displaystyle{Q(x) = -\lambda + x – \frac{43}{50} \cdot \log |x| – \frac{18}{25} \cdot \log |x-1| – \frac{7}{50} \cdot \log|x-2|,}\)
Calculus Exercise: Show that, with \(\lambda = 1.488753\ldots\), that \(Q(x) \ge 0\) for all \(x\) where it is defined. Deduce that the only totally real algebraic integer with \(T(\alpha) \le \lambda\) is \(\alpha = 1\). The graph is as follows:
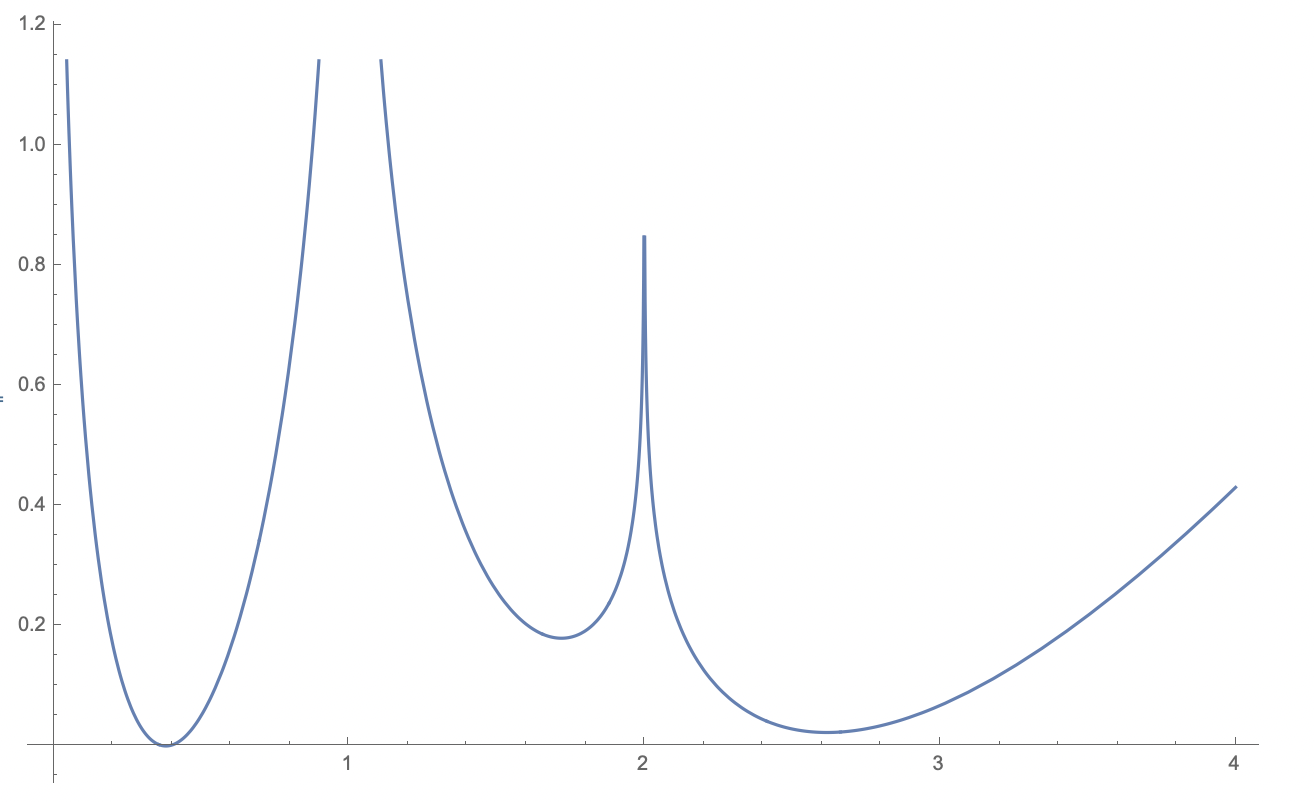
One can improve this by increasing \(\lambda\) and modifying the coefficients slightly, but note that we can’t possibly modify this with the given polynomials to get \(\lambda> 3/2\), because \(T(\phi^2) = 3/2\). Somewhat surprisingly, we can massage the coefficients reprove the theorem of Siegel and push this bound to \(3/2\). Namely, take
\(\displaystyle{Q(x) = -\frac{3}{2} + x – a \log |x| – (2a-1) \log |x-1| – (1-a) \log|x-2|,}\)
and note that the derivative satisfies
\(Q'(x)x(x-1)(x-2) = (x^2-3x+1)(x-2a),\)
Hence the minimum occurs at either \(x=2a\) or at the conjugates of \(\phi^2\) where \(\phi\) is the golden ratio. Since \(\phi^2-1 = \phi\) and \(\phi^2-2 = \phi^{-1}\), one finds that
\(Q(\phi^2) = -\frac{3}{2} + \phi^2 + (2-5 a) \log \phi,\)
and so chosing \(a\) so that this vanishes when, we get
\(\displaystyle{a = \frac{2}{5} + \frac{1}{2 \sqrt{5} \log \phi} = 0.864674\ldots} \)
and then we find that \(Q(x) \ge 0\) for all \(x\) where it is defined with equality at \(\phi^2\) and \(\phi^{-2}\). So this reproves Siegel’s theorem by elementary calculus. Of course we can strictly improve upon this result by including the polynomial \(x^2 -3x + 1\), for example, replacing \(Q(x)\) by
.
\(\displaystyle{P(x) = Q(x) – \frac{1}{15} \cdot \log |x^2 – 3x + 1| + \left(\frac{3}{2} – \lambda\right)}\)
where \(\lambda = 1.5444\ldots \) is now strictly greater than \(3/2\). By choosing enough polynomials and optimizing the coefficients by hook or crook, Smyth beat Siegel’s value of \(\lambda\) (even with an explicit list of exceptions), although he did not push \(\lambda\) all the way to \(2\). This left open the following problem: is \(2\) the first limit point? That is, does Siegel’s theorem hold for any \(\lambda < 2\)? This was already asked by Siegel and it became known as the Schur-Siegel-Smyth problem. Some point later, Serre made a very interesting observation about Smyth's argument. (Serre's original remarks were in some letter which was hard to track down, but a more recent exposition of these ideas is contained in this Bourbaki seminar.) He more or less proved that Smyth’s ideal could never prove that \(2\) was the first limit point. Serre basically observed that there existed a measure \(\mu\) on the positive real line (compactly supported) such that
\(\int \log |P(x)| d \mu \ge 0\)
for every polynomial \(P(x)\) with integer coefficients, and yet with
\(\int x d \mu = \lambda < 2\)
for some \(\lambda \sim 1.89\ldots \). Since Smyth’s method only used the positivity of these integrals as an ingredient, this means the optimal inequality one could obtain by these methods is bounded above by Serre’s \(\lambda\). On the other hand, Serre’s result certainly doesn’t imply that the first limit point of normalized traces of totally positive algebraic integers is less than \(2\). A polynomial with roots chosen uniformly from \(\mu\) will have normalized trace close to \(\lambda\), but it is not at all clear that one can deform the polynomial to have integral coefficients and still have roots that are all positive and real.
I for one felt that Serre’s construction pointed to a limitation of Smyth’s method. Take the example of \(Q(x)\) we considered above. We were able to prove the result for \(\lambda = 3/2\) by virtue of the fact that \(Q(x)=0\) at these points. But that required the fact that the three quantities:
\(\phi^2, \phi^2 -1 = \phi, \phi^2- 2 = \phi^{-1}\)
were all units and so of norm one. The more and more polynomials one inputs into Smyth’s method, the inequalities are optimal only when \(P_i(\alpha)\) is a unit for all the polynomials \(P_i\). But maybe there are arithmetic reasons why non-Chebychev polynomials (suitably shifted and normalized) must be far from being a unit when evaluated at \((\zeta + \zeta^{-1})^2\) for a root of unity \(\zeta\).
However, it turns out my intuition was completely wrong! Alex Smith has just proved that, for a measure \(\mu\) on (say) a compact subset of \(\mathbf{R}\) with countably many components and capacitance greater than one, that if Serre’s (necessary) inequality
\( \int \mathrm{log}|Q(x)| d \mu \ge 0\)
holds for every integer polynomial \(Q(x)\), then you can indeed find a sequence of polynomials with integer coefficients whose associated atomic measure is weakly converging to \(\mu\). In particular, this shows that Serre’s example actually proves the maximal \(\lambda\) in the Schur-Siegel-Smyth problem is strictly less than \(2\), and indeed is probably equal to something around \(1.81\) or so. Remarkable! I generally feel that my number theory intuition is pretty good, so I am always really excited when I am proved wrong, and this result is no exception.
Exercise for the reader: One minor consequence of Smith’s argument is that for any constant \(\varepsilon > 0\), there exist non-Chebyshev polynomials \(P(x) \in \mathbf{Z}[x]\) such that, for primes \(p\) say and primitive roots of unity \(\zeta\), one has
\( \displaystyle{\log \left| N_{\mathbf{Q}(\zeta)/\mathbf{Q}} P(\zeta + \zeta^{-1}) \right|} < \varepsilon [\mathbf{Q}(\zeta_p):\mathbf{Q}]\)
for all sufficiently large primes \(p\). Here by non-Chebyschev I mean to rule out “trivial” examples that one should think of as coming from circular units, for example with \(P(\zeta + \zeta^{-1}) = \zeta^k + \zeta^{-k}\) for some fixed \(k\). Is there any other immediate construction of such polynomials? For that matter, what are the best known bounds for the (normalized) norm of an element in \(\mathbf{Z}(\zeta)\) which is not equal to \(1\), and ruling out bounds of elements in the group generated by units and Galois conjugates of \(1-\zeta\)? I guess one expects the class number \(h^{+}\) of the totally real subfield field to be quite small, perhaps even \(1\) infinitely often. Then, assuming GRH, there should exist primes which split completely of order some bounded power of \(\log |\Delta_K|\), which gives an element of very small norm (bounded by some power of \([\mathbf{Q}(\zeta):\mathbf{Q}]\)). However, this both uses many conjectures and doesn’t come from a fixed polynomial. In the opposite direction, the most trivial example is to take the element \(2\) which has normalized norm \(2\), but I wonder if there is an easy improvement on that bound. There is an entire circle of questions here that seems interesting but may well have easy answers.